Running Integration Tests in Build Pipelines with a Real Database
Date Published: 16 October 2019

Last updated: 13 October 2023
A pain point for some organizations is figuring out how to run tests that involve databases. These are not unit tests, by most folks' definition (including my own: unit test or integration test and why you should care). Nonetheless, they're important and ideally they should run as part of your build pipeline. Recently I've come up with a technique that works quite well for this scenario that I'd like to share. But first let me describe some of the challenges teams encounter on this path.
Desired Automated Test Features
First, let's agree that, all things being equal, we'd like for our automated tests to be isolated, repeatable, and fast. It shouldn't matter what order we run them in. It shouldn't matter if we run them in parallel. It shouldn't matter when we run them. Every test should live in its own little branch of reality in which only it exists, and setting up and destroying that reality should take zero (or, preferably, negative) time and resources.
It's unlikely we'll be able to hit this ideal state, but it's worth calling out some of the things we're going for as we evaluate different options.
Option: No Integration Tests
"Integration tests are hard, so we're just not going to write any." (or perhaps, they're hard to run as part of the build so we run them on demand, maybe only before deployments)
Advantages: Saves lots of time writing tests and configuring build pipelines to run them!
Disadvantages: That time savings is rapidly lost to repetitive manual testing and shipping of preventable bugs to unappreciative users.
Option: InMemory Database
A common approach (that I've used often) is to run integration tests using an in-memory data store. In .NET Core this is very easily configured using EF Core's InMemory configuration option. It works for basic testing that your CRUD statements mostly work, but has a lot of differences from a real database that often cause problems (that have nothing to do with problems in your code and everything to do with problems with this provider). For instance, there's no notion of eager or explicit or lazy loading - related properties of entities are always available. Ids are tracked globally and resetting them reliably can be difficult, resulting in issues when entities are added without explicitly setting their IDs and then relying on repeatable behavior of tests run in any sequence. Any logic depending on LINQ to Entities won't be executed.
Advantages: Easy to set up, very fast, no external dependencies.
Disadvantages: Many differences from a real database, and in how EF behaves compared to when it's hitting a real database. These differences don't always matter to what you're trying to test, but when they do (and even sometimes when they don't), they can cause a lot of pain.
Option: Shared Test Database
That's fine, you say, we'll just use a test database. Great! This can work, but it's best in the smallest of teams since it's usually cost and time prohibitive to stand up a separate new test database for every test or test run, so generally the same test database is used for these integration tests. And often for other things as well, like QA doing their manual testing. Basically, the more things hitting the shared database, the more likely it is that you'll see test failures because of data problems caused by shared use than real test failures that are detecting problems in your system.
Keeping the data and schema of the test db up-to-date with changes made in development (or sometimes even in production) can be a challenge. Restoring the database to a known good state before test runs (and, ideally, before individual tests) is often difficult or frowned upon by other teams relying on the database.
Advantages: Maybe you can recycle the test db that your QA team uses as the backend for their test environment!
Disadvantages: Prospect of false positive failing tests is high due to shared use of the database. Very little isolation for integration tests. Even if only integration tests are hitting the database, parallel test runs (in a single build pipeline instance or as multiple build agents run tests at the same time) can be problematic.
So, what then?
There are a bunch of options listed above and none of them really come close to our ideal for integration tests, which admittedly are much more difficult to get to approach the ideal state than unit tests. But what if you could package up the database with your integration tests, as a real SQL Server instance, and you could have each build agent pull it down along with your tests and run your tests against it in complete isolation from other build agents (and anyone else running tests in your organization)?
Through the magic of Docker, you can!
Option: Dockerized Database Deployed with Tests
Did you know SQL Server runs on linux? Did you know you can pull it down from the internet and have it running with a couple of lines in a text file? If you didn't, I forgive you - it's kind of crazy if you think about it. But you totally can.
I have a Nuget package, Ardalis.Specification, that relies on EF Core and how it communicates with a real database. An InMemory database would not let me adequately test that this tool works correctly. Naturally I wanted to configure CI/CD for the project, but I needed to be able to reliably run integration tests against a real SQL database. None of the options at the start of this article appealed to me, so I went down the Docker path and came up with a solution I'm really happy with.
Basically, I'm using Docker Compose to set up tests in one container and my database in another container. There's a tool I use to monitor the database container from the test container, so that the tests don't start to run until the database has come online (which takes a few moments). Then, the tests all run, code coverage is collected, and the build succeeds or fails as expected! Most of this is defined in the dockerfile.
Note that you don't have to rely on docker-compose - I've also used a very similar approach for a client of mine already that is just a PowerShell script.
Here's the Docker compose file. The tests service is my stuff; the database service is just a stock SQL Server container from Microsoft's container registry.
version: '3.4'
services:
tests:
build:
context: .
dockerfile: Dockerfile
environment:
WAIT_HOSTS: database:1433
volumes:
- ./TestResults:/var/temp
database:
image: mcr.microsoft.com/mssql/server:2017-CU8-ubuntu
environment:
SA_PASSWORD: "P@ssW0rd!"
ACCEPT_EULA: "Y"My Dockerfile is next. It just copies my source into a container that has the .NET Core SDK installed on it, adds the "wait" command which will poll a port until it gets a response, and then runs all of the tests after the wait command confirms that SQL Server is up and listening on port 1433 (defined above in the WAIT_HOSTS variable in the docker-compose.yml file).
FROM mcr.microsoft.com/dotnet/core/sdk:2.2 AS build
WORKDIR /app
COPY . ./
ADD https://github.com/ufoscout/docker-compose-wait/releases/download/2.5.0/wait /wait
#RUN chmod +x /wait
RUN /bin/bash -c 'ls -la /wait; chmod +x /wait; ls -la /wait'
CMD /wait && dotnet test --logger trx --results-directory /var/temp /p:CollectCoverage=true /p:CoverletOutputFormat=cobertura && mv /app/tests/Ardalis.Specification.UnitTests/coverage.cobertura.xml /var/temp/coverage.unit.cobertura.xml && mv /app/tests/Ardalis.Specification.IntegrationTests/coverage.cobertura.xml /var/temp/coverage.integration.cobertura.xmlAnd here's the simple RunTests script that I call from the build pipeline or command line to run everything. It just makes sure to re-build the container every time so that when I run locally it picks up changes I've just made:
docker-compose build
docker-compose up --abort-on-container-exitRunning the script results in:
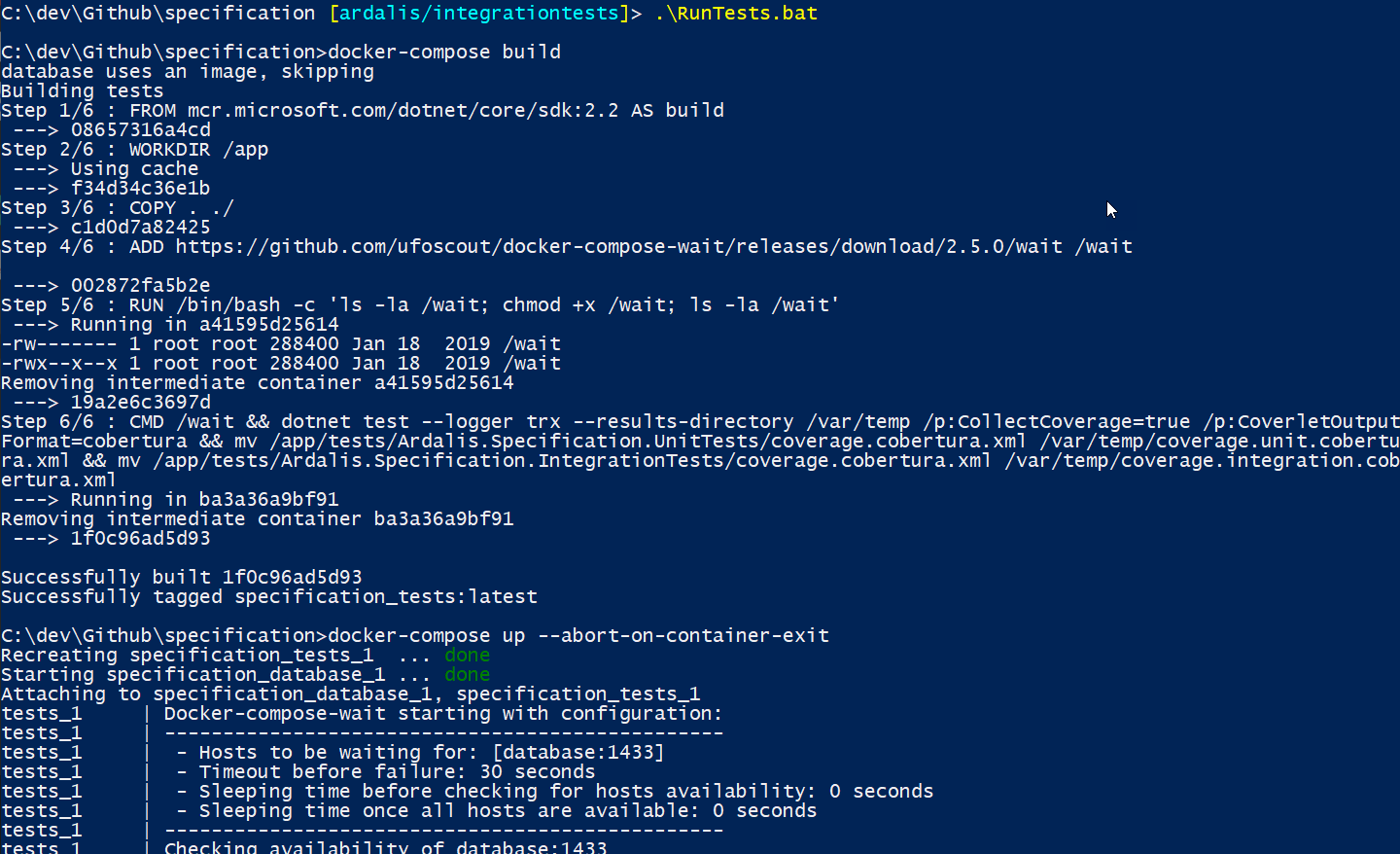
Running docker-compose from ps script to kick off integration tests.
In the image above you can see the container being built at the top with each "Step N/6" shown. Then the wait command is called on my container while simultaneously the SQL Server image starts up. My container's log output starts with "tests_1" and you can see the wait command is polling port 1433 waiting for a response. There nothing so far from the SQL Server container.
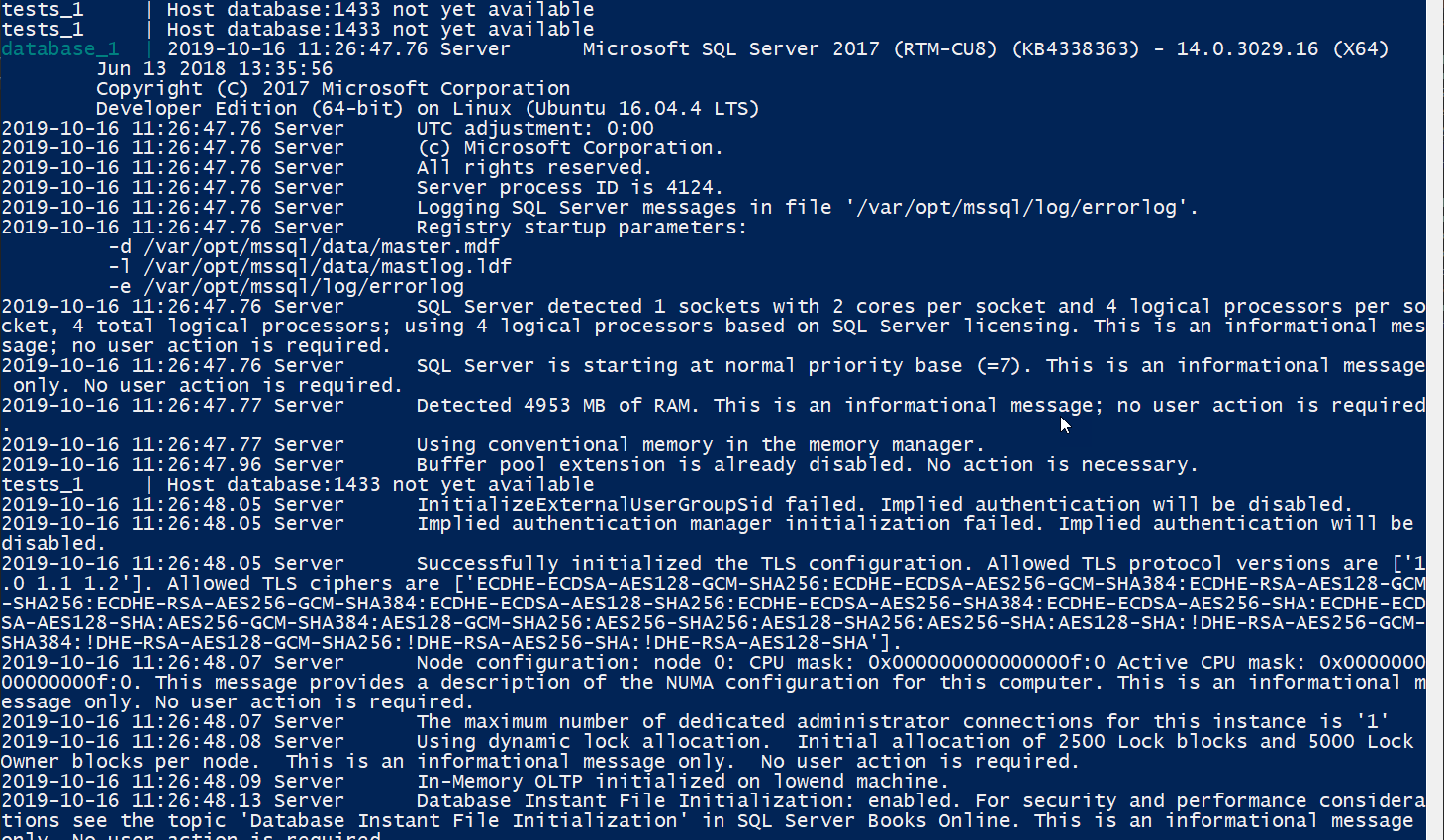
SQL Server in a container starting up.
After a few seconds, SQL Server starts outputting stuff to the log output (console) as it starts up. Eventually, it's ready for connections:

SQL Server container becomes ready.
At this point, all the tests start running, starting with unit tests, which include code coverage output which is displayed in the console and dumped to a coverage file (used on the build server to build a report):
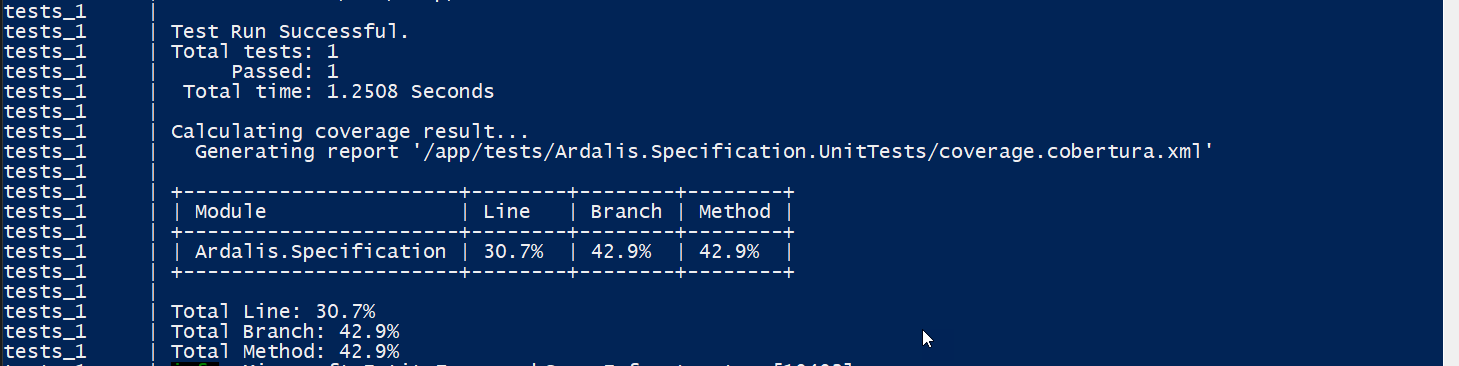
Unit tests with code coverage.
Next the integration tests run. You can see the actual SQL commands being generated and run by EF Core in the log output, proving that we're actually talking to a database, not an InMemory provider:
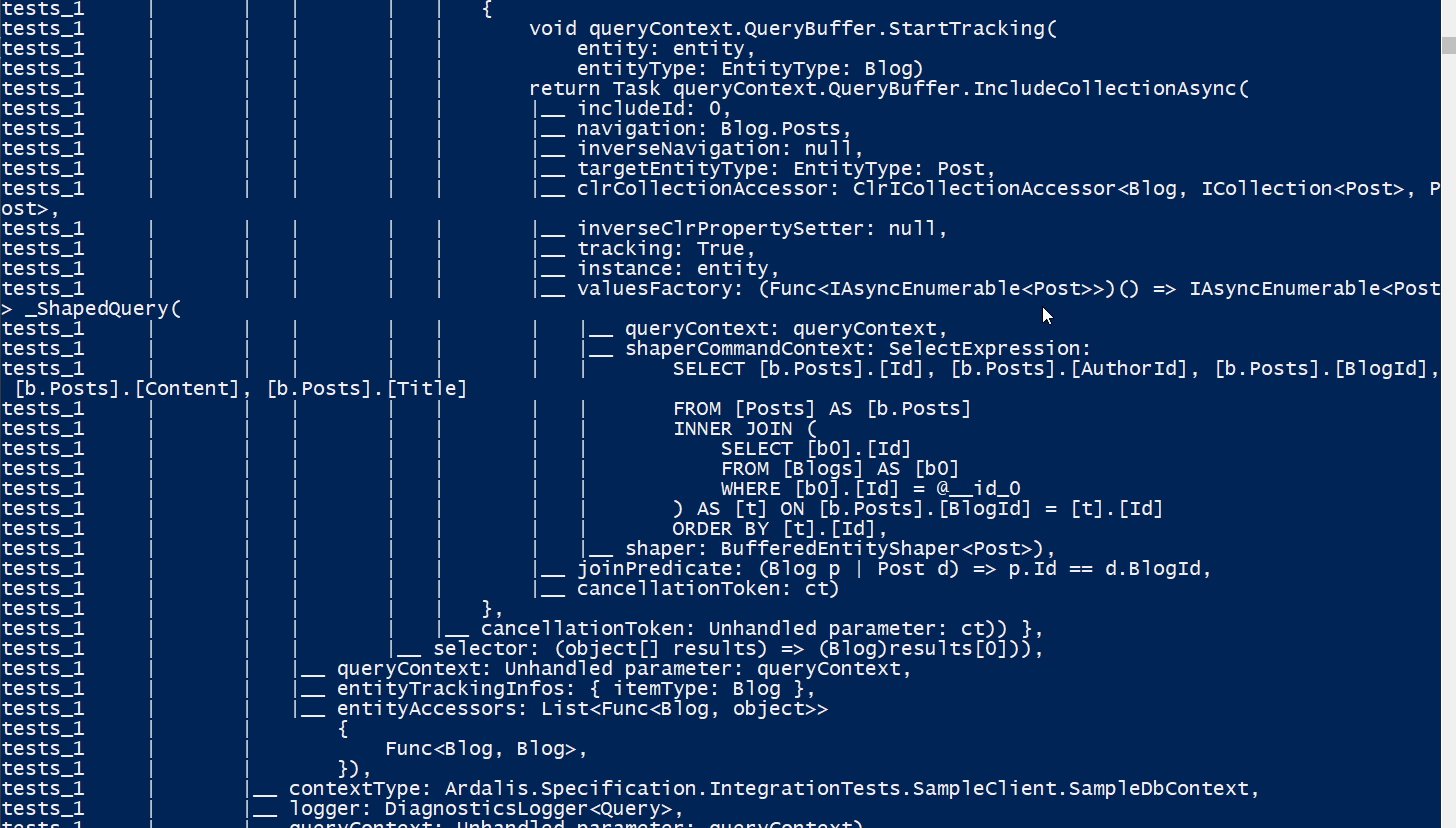
Why yes you can run SQL commands against your own db in a build pipeline.
And finally, the build completes, code coverage is reported for the integration tests, and the containers stop and exit.
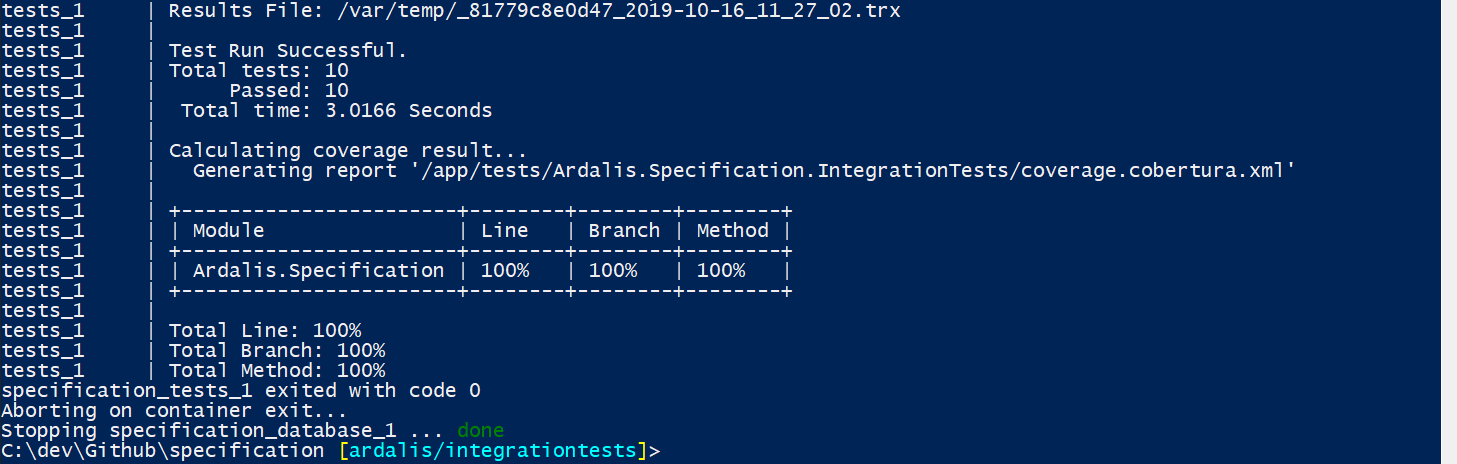
Just another day with 100% code coverage.
Get the code
All the code for this is in my Ardalis.Specification GitHub Repository. It has an Azure DevOps build configured and will eventually have a GitHub Actions pipeline set up. Right now there's an issue in the Azure pipeline with publishing the code coverage results, but that's a separate thing from everything described in this article, which works just fine.
The Ardalis.Specification Nuget package lets you separate your query logic from the rest of your code. You can see it in action in the Microsoft eShopOnWeb reference application that I maintain. The pattern helps avoid leaking data access and query logic throughout your app, gives you reusable and testable queries, can be combined with patterns like the CachedRepository, and keeps your Repository implementations small and focused. I describe it in the Pluralsight Design Pattern Library if you want to learn more (it's the last one in the list).
Thanks!
Hey, thanks for reading this long article. If you found it helpful, please share it with others. One easy way to do so if you use twitter is to click on this tweet and just retweet it to your followers. They'll thank you and so will I!
Running Integration Tests in Build Pipelines with a Real Databasehttps://t.co/7royudyHPD#docker #sqlserver #azuredevops #efcore
— ? Steve "ardalis" Smith ? (@ardalis) October 16, 2019
Category - Browse all categories

About Ardalis
Software Architect
Steve is an experienced software architect and trainer, focusing on code quality and Domain-Driven Design with .NET.
