Scaling Redis
Date Published: 14 November 2022

Redis is a popular open source cache server. When you have a web application that reaches the point of needing more than one front end server, or which has a database that's under too much load, introducing a Redis server between the application server and its database is a common approach. However, sometimes a single redis server is insufficient for the required load and performance requirements. When you need more performance than a single redis instance can offer, you need to consider how you're going to be scaling redis in your application's architecture. This article goes into detail on how to work with Redis and scale it using the built-in clustering tools. In addition, we'll look at an alternative using ScaleOut In-Memory Database™, which offers several advantages over the built-in solution.
NOTE: I've known the team at ScaleOut Software for over a decade. They're an extremely nice and talented group, and they provided me with a hosting environment and other consideration for this article and its associated video. While they did provide technical assistance on the tests and evaluation performed, any errors should be considered my own.
Starting Small
Let's begin by assuming we have a need for a cache solution like Redis in the first place. Imagine you are working with a simple web app that talks to a backend database. Your initial architecture looks something like this:
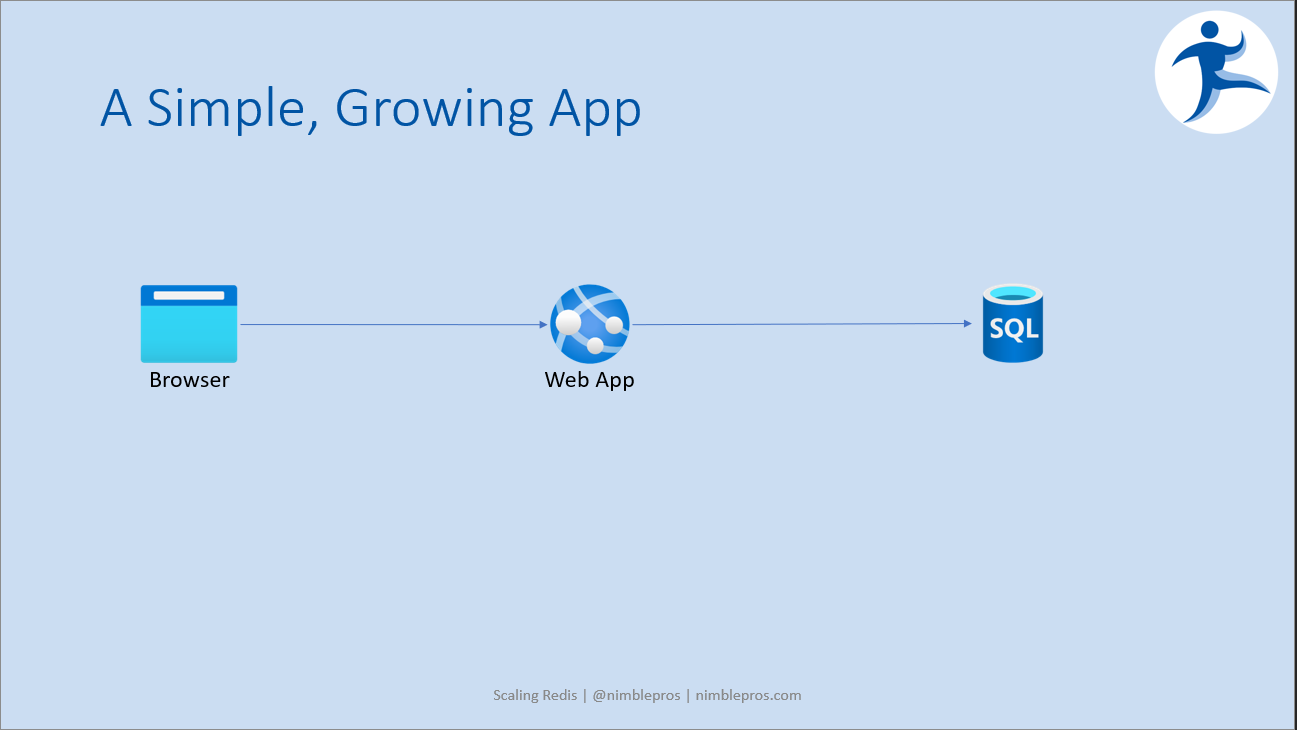
Your initial architecture is incredibly simple. Browsers make requests to your app, and your app in turn makes requests to the database to get or modify data. However, as traffic has grown, load on the database has increased and the speed of responses to the browser has decreased during peak periods.
You decide the simplest solution to this problem is to introduce a cache server, namely Redis, and to modify your app to check if a given data result is in Redis before seeking it in the database itself.
Adding a Single Redis Server Instance
It's pretty straightforward to install a single Redis instance. After provisioning a unix VM, just run the following commands:
$ sudo apt update
(done)
$ sudo apt install redis-tools
(done)
$ sudo apt install redis-server
(done)
redis-cli
127.0.0.1:6379> ping
PONGYou can use the StackExchange.Redis client to connect to your Redis server from your .NET app. Typically you will apply the cache aside pattern, checking the cache first, and only fetching from the database when the item sought isn't in the cache (or has expired which equates to the same thing). After fetching from the database, the item is stored in the cache so it's available the next time it's requested.
After adding a Redis cache server to your architecture, things now look like this:
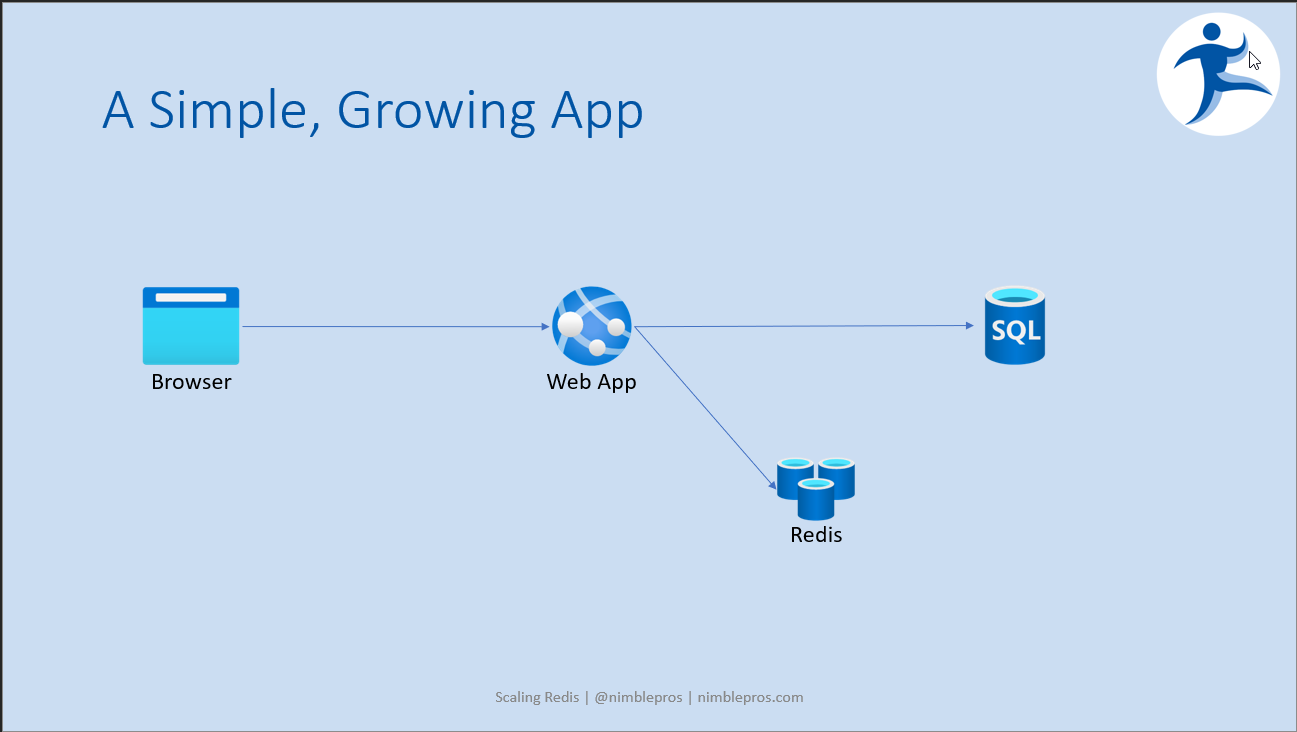
Of course, for both scalability and availability reasons, we're going to want to horizontally scale the web app. And along with scaling the web servers, in order to remove the single point of failure, we'll also want to add additional Redis caches. An initial naive approach might look like this (scale the webserver-cache pairs):
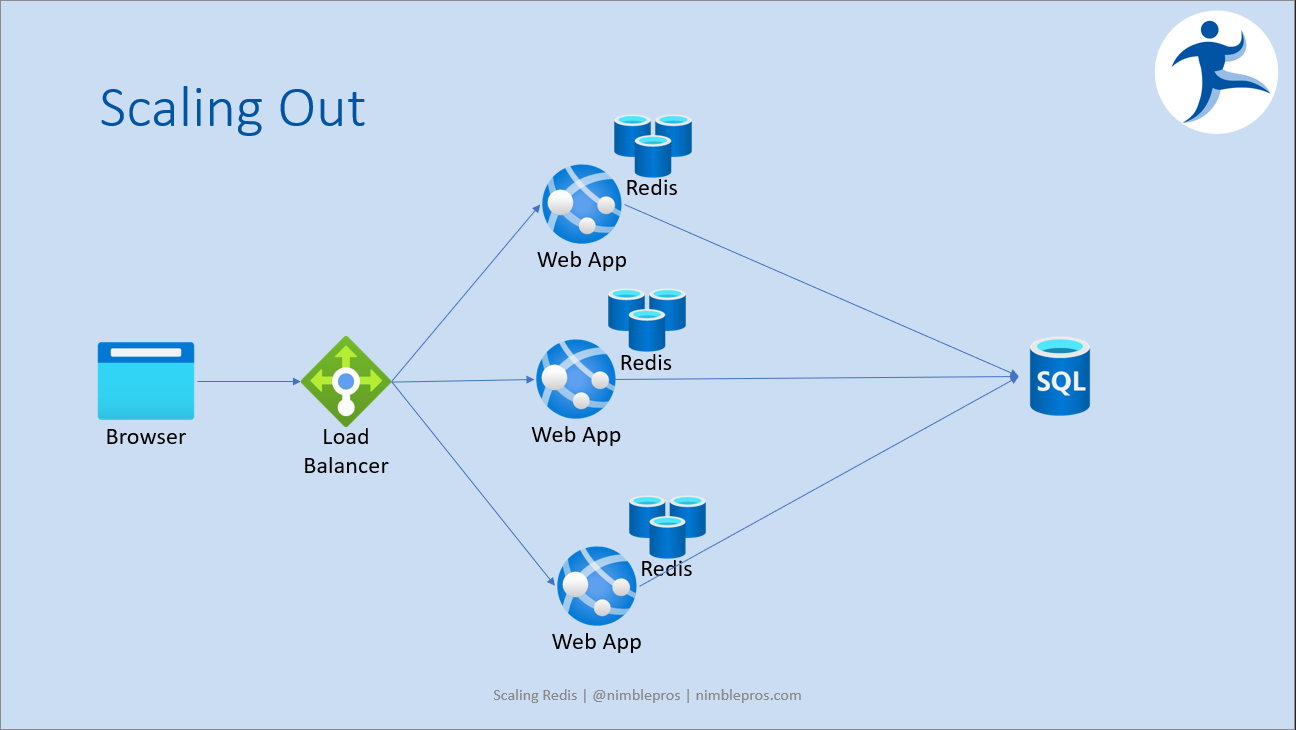
The problem with this design is data synchronization. The web apps are, presumably, stateless, but the Redis instances are not. A request may be served by the first app which has one version of the data in its cache, and the next request may be served by a different web app, with a separate redis instance associated with it and different, perhaps older, data in its cache. This can be mitigated through the use of sticky sessions at the load balancer, but that's not an ideal solution for scalability. What we need is a way to scale the redis servers while keeping their contents synchronized. Redis has a scaling solution - it's a Redis Cluster.
Scaling Redis with Redis Cluster
From the docs:
Redis scales horizontally with a deployment topology called Redis Cluster. Redis Cluster provides a way to run a Redis installation where data is automatically sharded across multiple Redis nodes.
We want to take our 3 separate Redis instances and make a cluster out of them, so that all three webservers get the same data back consistently when working with the cache. Let's follow the docs for setting up a redis cache.
Redis Cluster 101
First, some background in the "Redis Cluster 101" section, which I'll summarize in bullets:
- Data is sharded automatically across multiple Redis nodes
- Some availability during partitions (Cluster can stay up when a node is disconnected or down)
- Requires two ports: 6379 (standard Redis port) and a cluster bus port 16379 (typically)
- Some considerations when running with Docker: must use host networking mode
- Keys belong to hash slots
- There are 16384 hash slots
- Hash slots are computed by taking the CRC16 of the key, modulo 16384
- Each Redis node is responsible for a set of hash slots
- Moving hash slots becomes important when adding/removing nodes to/from the cluster
- Redis uses a master-replica model, with the replica acting as a hot backup of its master
- Redis does not guarantee strong consistency
- "it is possible that Redis Cluster will lose writes that were acknowledged ty the system to the client"
- There is a tradeoff between speed and consistency; Redis favors speed
- The node timeout configuration is very important to understand and consider regarding timeouts
Ok, on to the next section of the docs, "Redis Cluster configuration parameters.
Redis Cluster configuration parameters
These are found and set in the redis.conf file.
- cluster-enabled. Obviously very important. Must be yes to use a cluster.
- cluster-config-file. The filename that will hold certain redis cluster settings (not a user file)
- cluster-node-timeout. How long a node can be unavailable (in milliseconds) before it fails over.
There were a few more settings but none I needed to use. Which brings us to the next section of the docs, "Create an use a Redis Cluster."
Create and use a Redis Cluster
To create a cluster, the first thing you need is to have a few Redis instances running in cluster mode.
Recall that we have 3 Redis instances from above, so we should just need to put them into "cluster mode". The docs go on to show the following as the minimal settings we need to configure in redis.conf:

Note: We don't want to change the default port so we'll keep 6379.
Ok, so to set this up we just need to ssh into each linux VM and edit its redis.conf file to make these changes. We have 3 nodes so it's a bit tedious but not so large a task that it's worth scripting (IMO). Here's an example of what you need:
> ssh -i ".ssh/ss.pem" ss@dev1
Enter passphrase for key '.ssh/ss.pem':
> sudo nano /etc/redis/redis.confNote that path of /etc/redis/redis.conf. Nothing in the Redis Cluster docs tells you this is where the Redis configuration file is located (though it's probably mentioned elsewhere).
Oh, but what's this?

Great... so now I need to double the hardware I was planning on using. And also, twice as many config files to manually edit. But I guess this is how we live now.

Ok, so spin up 3 more linux machines/VMs, configure them for ssh, install Redis, ssh into them, edit the config files, set up the minimal settings. Whew!
Create a Redis Cluster
Now we're ready to use the redis-cli to create a cluster. The syntax is pretty straightforward; just pass in --cluster create and a list of IP:port combinations. If you're configuring replicas (we are), you need to add --cluster-replicas 1 at the end (or however many replicas you want for each master). With 6 nodes (6 IP/port combos) and cluster-replicas 1, you'll get 3 master nodes and 3 replica nodes.
I run the command, and it fails with this:
Could not connect to Redis at dev2:6379: Connection refusedTroubleshooting Redis Cluster Creation
If your create cluster command fails, despite following the docs, it may be because of one of these undocumented requirements.
First, by default your newly-installed Redis servers will probably be configured in protected mode. Look for protected-mode and make sure it's configured to no in your redis.conf file. You'll probably need to also restart your redis service, using this command:
sudo /etc/init.d/redis-server restartYou can try your redis cluster create command once this has been modified. If it still fails, there's another undocumented setting you should check, which is bind 127.0.0.1 ::1. Look for this setting in your redis.conf file and comment it out if you see it. Essentially it instructs the server to only listen to requests from localhost. If you're using a Redis server that was already in production, this setting probably isn't in place, but if you just created some new installs (ahem, because you needed more instances for replicas) then it's likely the new ones will have this set by default.
Try the cluster create command again, and hopefully it works.
It's working
Assuming you have it working now, the call to redis-cli --cluster create should return with info about the proposed cluster configuration. For example:
>>> Performing has slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica (ip) to (ip)
Adding replica (ip) to (ip)
Adding replica (ip) to (ip)
...
Can I set the above configuration? (type 'yes' to accept): _Type yes and the Redis Cluster should (finally) be created!
Working with Redis Cluster
You need a cluster-aware client to work with Redis Cluster. Even the redis-cli command requires a flag to be cluster-aware (-c), as you can see here:
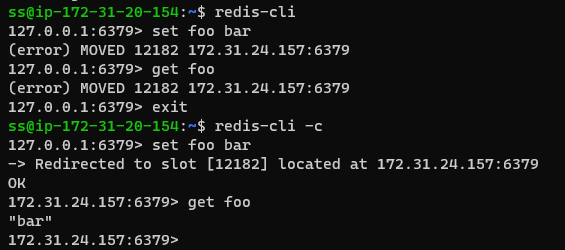
Clients like the .NET StackExchange Redis Client are also cluster-aware by default.
Administering a Redis Cluster
Ok, now we have a working Redis Cluster. Let's consider some common administrative tasks we expect to perform on it.
First, what happens to the data in an existing Redis server when it's added to the cluster?
Unfortunately, you can't just add an existing Redis server to the cluster if is has data. You can only add empty nodes. So, you'll need to write a script to back up the data elsewhere, add it, and then pull the data back in, if you need the data. Otherwise, you can use the flushall command to eliminate all of the data before adding it.
What happens when a new node is added to the cluster?
You might expect that adding a 4th node to a 3-node cluster would automatically split the hash slots between the 4 nodes. Unfortunately, this is not the case. When you add more nodes, nothing happens to the existing nodes, and all hash slots (and load) continues to only use the original nodes. You need to manually rebalance the cluster.
redis-cli --cluster rebalance dev1:6379Unfortunately, the above command will simply tell you that the cluster is already balanced (assuming it was). It won't do anything with your shiny new empty 4th node. You need to explicitly instruct it to use the new node using the cluster-use-empty-masters flag:
redis-cli --cluster rebalance dev1:6379 --cluster-use-empty-mastersThis should result in a rebalancing that may take a few minutes. When it's complete, you can run this command to view cluster status:
redis-cli --cluster check dev1:6379Unfortunately, while you might have had nice contiguous blocks of hashsets upon initial creation of the cluster, you're likely now going to have a mess, with random hashslots assigned in a very fragmented manner, resulting in very verbose output like this:
~showing hashslot fragmentation in results of a cluster check command
Your best bet to avoid this is to destroy the cluster and re-create it from scratch. Note that nowhere in the docs does it tell you how to reset your now-cluster-enabled Redis nodes, such that re-clustering them will start fresh.
You may also want to remove a node from the cluster, rebalancing the cluster among the remaining nodes. There's no automatic way to do this, either. You must first either run flushall on the node you're removing (destroying all data on it) or use a script like this one to migrate its data to another node. Once empty, you can run this command to remove the node (providing the key for the node being removed):
redis-cli --cluster del-node dev1:6379 a8b445...97c Once this is done, your remaining nodes are likely not balanced (if your script moved everything from the deleted node to one other node), so you'll need to rebalance:
redis-cli --cluster rebalance dev1:6379Redis Cluster Review
It's been a bit of a journey (and this took me quite a while to get working, myself), so let's review where we are to this point.
- Started with 3 Redis servers
- Needed 3 more to support 3 replicas for recommended production config
- Had to change config files. So many times. For all 6 nodes.
- The
redis-clidoes the job, mostly, but is very low level - Doing this required immense attention to detail and was exceedingly error prone
So, here is where we move away from Redis for a moment and consider a commercial offering. If you're happy with Redis or don't have the budget for something better, then hopefully at least the above helped you get your cluster set up. If your app has serious performance and reliability needs (and some budget to meet these needs), keep reading.
ScaleOut In-Memory Database™
ScaleOut In-Memory Database™ (or SOSS/soss for the CLI tool, which originally worked with ScaleOut StateServer, hence the name) is a distributed In-Memory Database that has integral Redis support. That means you can set it up and just point your existing Redis clients at it (update their IP/port), and everything will continue to work without any code changes required. There's also a separate ScaleOut client, but you don't have to commit to using it to try out SOSS on the server as a drop-in replacement for Redis/Redis Cluster.
Installing ScaleOut In-Memory Database™
Installing ScaleOut In-Memory Database™ is pretty simple. Get the installer file appropriate to your server's OS from their website. Send it to your server via scp (or pull it using wget, etc.). Finally, install the file using a command like this one:
sudo dpkg -i soss_5.12.1.376_amd64.deb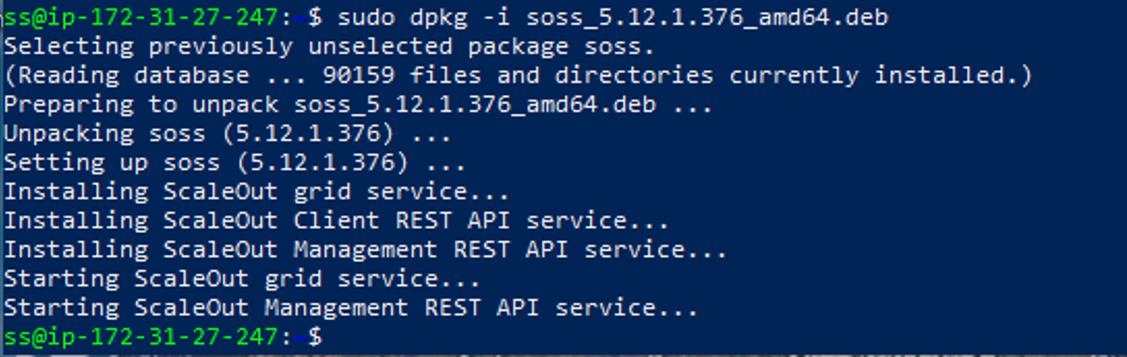
That's it. By default the soss service runs on port 721. Join the subsequent nodes to the first using soss join:
soss join (ip address of existing soss instance)You can immediately verify it's working as a Redis server by connecting to it with redis-cli (and using the cluster flag -c):
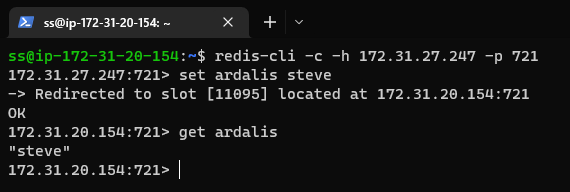
The soss cli utility has commands for managing the cluster, including joining and leaving, restarting, and clearing data, among others. It doesn't have low level commands for resharding or balancing keys, since these are all done automatically and internally. The SOSS In-Memory Database is self-healing, so if a node fails, the cluster takes care of rebalancing on its own, without user intervention. If I were responsible for being on call if there's a problem, I'd much rather have a self-healing product than one that's going to page me in the middle of the night and require me to remember or locate complicated scripts or CLI commands to rebuild or fix the cluster.
Benchmarks
I used BenchmarkDotNet and a small application running on the same network as the SOSS and Redis clusters to run some basic performance tests. The test application performs a certain number of writes (WRITE_COUNT). Each write operation writes a certain number of bytes (PAYLOAD_BYTES) to the cluster using a GUID key. Then, it reads the data from this key a configured number of times (READ_RATIO). I ran the application like this:
dotnet run -c Release -- --envVars REDIS_SERVERS:172.31.20.154__6379,172.31.24.157__6379,172.31.27.247__6379 READ_RATIO:100 WRITE_COUNT:10 PAYLOAD_BYTES:20000 SOSS_SERVERS:172.31.20.154__721,172.31.24.157__721,172.31.27.247__721Here are the results (10 writes, 100 reads per write, 20000 byte payload):
| Method | Mean | Error | StdDev | Percent |
|---|---|---|---|---|
| Write/Read to Redis | 295.7 ms | 5.89 ms | 13.17 ms | 182% |
| Write/Read to Soss | 161.9 ms | 3.40 ms | 9.96 ms | 100% |
NOTE: In this benchmark, Soss outperforms Redis even though Soss offers consistency guarantees and Redis does not. One potential reason I had considered for the improved performance is the presence of some built-in caching in the Soss .NET client. I ran additional tests to account for this by reducing the read ratio to just one read per write (thus eliminating the value of any client side cache):
dotnet run -c Release -- --envVars REDIS_SERVERS:172.31.20.154__6379,172.31.24.157__6379,172.31.27.247__6379 READ_RATIO:1 WRITE_COUNT:10 PAYLOAD_BYTES:20000 SOSS_SERVERS:172.31.20.154__721,172.31.24.157__721,172.31.27.247__721Here are the results (10 writes, 1 read per write, 20000 byte payload):
| Method | Mean | Error | StdDev | Percent |
|---|---|---|---|---|
| Write/Read to Redis | 46.82 ms | 1.38 ms | 4.01 ms | 542% |
| Write/Read to Soss | 8.631 ms | 0.17 ms | 0.36 ms | 100% |
Surprisingly, the difference is even more pronounced in this case. While it's true that in both cases, the requests to the cache cluster is likely to be much faster than similar requests to the database, it's clear that the Soss cluster access with its .NET client has a significant performance advantage over the Redis cluster accessed with its .NET client.
Summary
I learned a great deal while researching this article. I'll include many of the references I used at the bottom. It had been some time since I'd worked with linux machines, and so it took a bit of time for me to get back up to speed with the process (I'd used telnet, ftp, emacs but now I'm using ssh, scp, nano). I've also done a lot with .NET apps on Windows, MacOS, and even in Linux docker containers, but I hadn't run them directly inside of Linux VMs. What's more, I had only limited experience with Redis, none with SOSS, and had only read about Benchmark.NET. I think this made me a stronger reviewer, since I didn't have any built-in assumptions or knowledge about how the process should work. However, if you're a very experienced Redis administrator, you may have no problem dealing with Redis clusters and their unique challenges. Experience is the best teacher, and you probably have the scars to prove it. Personally, I'd rather be building apps than administering cache clusters, so whichever service meets the business's needs within budget and requires the least effort to set up and maintain, that's probably what I'll opt for given the choice.
References
- Scaling with Redis Cluster
- Redis Cluster - 3 Master Nodes Minimum
- How to connect to remote redis server
- Install Redis on Ubuntu
- How to install Redis Server on Ubuntu
- Create a Redis Cluster
- How to Edit and Save a file through Ubuntu Terminal
- How can I stop Redis Server
- Redis Issue: Node is not empty error
- Redis fatal error: can't open config file
- Ubuntu list services command
- Could not connect to Redis at 127.0.0-16379 connection refused
- Deleting Master Node from Existing Redis Cluster
- Redis nodes.conf file locked?
- Install and use .NET Core on Debian Linux
- SOSS .NET Client - Connecting
- SOSS In Memory Database
- SOSS User Guide - Installation - Parameters
- SOSS Docs - .NET Client
- SOSS Docs - Quickstart
- StackExchange.Redis Client Nuget Package
- Scaleout.Client Nuget Package
- BenchmarkDotNet
- SOSS Redis vs ScaleOut: What You Need to Know
Category - Browse all categories

About Ardalis
Software Architect
Steve is an experienced software architect and trainer, focusing on code quality and Domain-Driven Design with .NET.

{kind=link}
{kind=link}