Detect Unicode Usage in SQL Column and Optimize Storage
Date Published: 28 April 2010

Last Updated: May 2024
One optimization you can make to a SQL table that is overly large is to change from nvarchar (or nchar) to varchar (or char). Doing so will cut the size used by the data in half, from 2 bytes per character (+ 2 bytes of overhead for varchar) to only 1 byte per character. However, you will lose the ability to store Unicode characters, such as those used by many non-English alphabets, as well as emoji characters.
If the tables are storing user-input, and your application is or might one day be used internationally, using Unicode for your characters is most likely the correct approach. I don't recommend changing to a non-Unicode format in such cases.
However, if instead the data is being generated by your application itself or your development team (such as lookup data), and you can be certain that Unicode character sets are not required, then switching such columns to varchar/char can be an easy improvement to make.
Avoid Premature Optimization
If you are working with a lookup table that has a small number of rows, and is only ever referenced in the application by its numeric ID column, then you won't see any benefit to using varchar vs. nvarchar. More generally, for small tables, you won't see any significant benefit. Small being, under 1 million rows, let's say. Thus, if you have a general policy in place to use nvarchar/nchar because it offers more flexibility, do not take this post as a recommendation to go against this policy anywhere you can.
You really only want to act on measurable evidence that suggests that using Unicode is resulting in a problem, and that you won't lose anything by switching to varchar/char.
Obviously the main reason to make this change is to reduce the amount of space required by each row. This in turn affects how many rows SQL Server can page through at a time, and can also impact index size and how much disk I/O is required to respond to queries, etc. If for example you have a table with 100 million records in it and this table has a column of type nchar(5), this column will use 5 * 2 = 10 bytes per row, and with 100M rows that works out to 10 bytes * 100 million = 1000 MBytes or 1GB. If it turns out that this column only ever stores ASCII characters, then changing it to char(5) would reduce this to 5*1 = 5 bytes per row, and only 500MB. Of course, if it turns out that it only ever stores the values "true" and "false" then you could go further and replace it with a bit data type which uses only 1 byte per row (100MB total).
Detecting Whether Unicode Is In Use
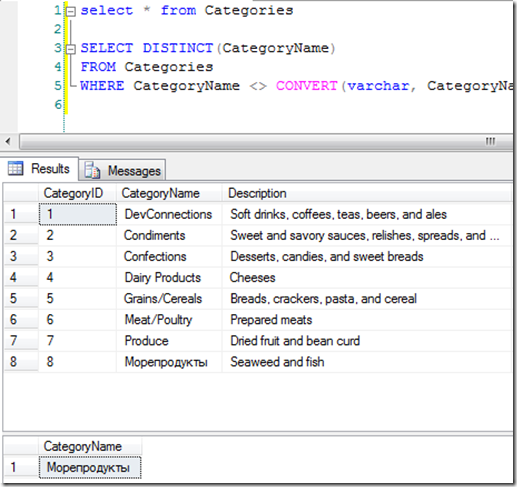
So by now you think that you have a problem and that it might be alleviated by switching some columns from nvarchar/nchar to varchar/char – but you're not sure whether you're currently using Unicode in these columns. By definition, you should only be thinking about this for a column that has a lot of rows in it, since the benefits just aren't there for a small table, so you can't just eyeball it and look for any non-ASCII characters. Instead, you need a query. It's actually very simple:
SELECT DISTINCT(CategoryName)
FROM Categories
WHERE CategoryName <> CONVERT(varchar, CategoryName)I tested this out on the Northwind database, which has a Categories table. Categories has a Category Name column that is nvarchar(15). I updated the Seafood row to be Russian:
Морепродукты
Obviously this uses some non-ASCII characters. Detecting them is easy using the above query, as you can see here:
Summary
Converting data types from Unicode (nvarchar/nchar) can cut the size required to store the data by half, which can be a fairly easy optimization to make. However, this will usually only make a significant difference for tables with millions of rows. In that case, it's worth considering, but you'll want to detect whether the table has any Unicode characters in it before you convert it to varchar/char. Doing so is straightforward using the comparison shown here.
Remember, avoid doing this for data that accepts user input, or that may need to require additional characters (non-ascii) in the future. You will need to modify the table schema to accommodate that in the future after making this change.
Thanks to Gregg Stark for the tip.
Keep Up With Me
If you're looking for more content from me in your inbox subscribe to my weekly tips newsletter and be sure to follow me on YouTube.
Category - Browse all categories

About Ardalis
Software Architect
Steve is an experienced software architect and trainer, focusing on code quality and Domain-Driven Design with .NET.
