Cloud Messaging – Amazon or Azure?
Date Published: 15 March 2017
When architecting solutions that need to communicate between separate services or applications,messages queues and services buses become increasingly important. Both Microsoft Azure and Amazon AWS offer products that support these operations, essentially allowing you to efficiently send text-based messages from one application to another. There are many benefits to this approach over directly communicating from one application to another. You allow for the destination service to be unavailable from time to time without losing messages – when it comes back online, it empties the queue and the sender never sees any errors. You also allow for applications to communicate with other applications they don’t know about when they’re deployed. Once the app is configured to send to a service bus or SNS topic, it’s easy for additional handlers to subscribe to messages without the need to change the sending application.
Which do you choose?
Microsoft Azure Service Bus and Amazon Simple Notification Service (SNS) and Simple Queuing Service (SQS) offer similar capabilities. Their pricing no doubt varies, but they tend to be fairly close and if you’re not sending huge numbers of messages they shouldn’t be a huge factor in your application’s budget. If your latency is a concern and your application is hosted in one of these two providers, you should default to using the infrastructure that’s available from that same provider (ideally from the same region / data center). However, if you’re communicating between data centers in any case, it probably won’t much matter which cloud provider you choose. You can set either one up in a configuration like this one:
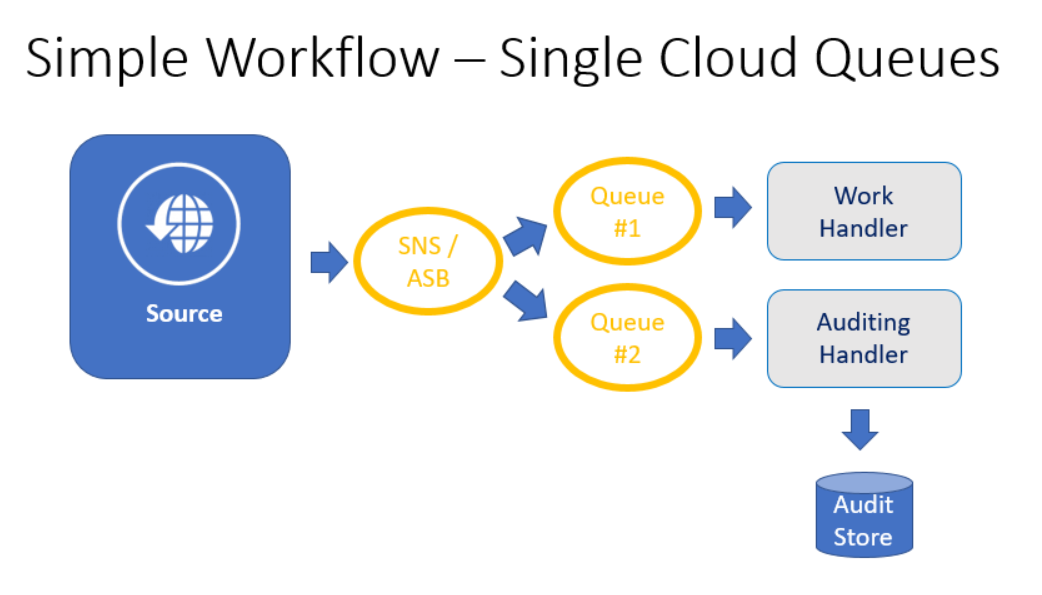
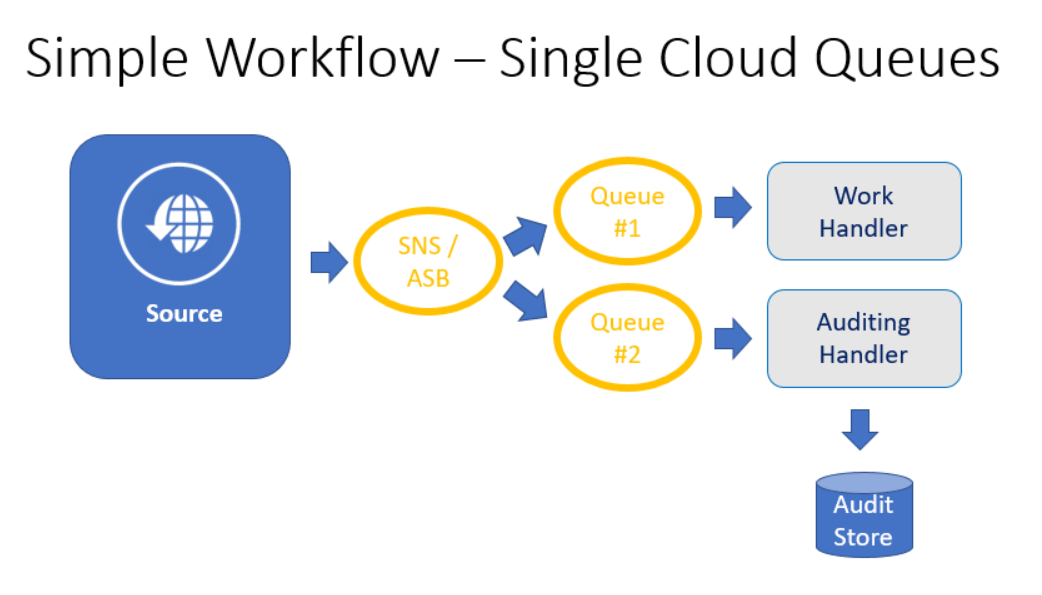
In this approach, a single SNS or Azure Service Bus can support multiple downstream queues or topics that subscribe to messages sent to it. One or more handlers can then listen to these queues, performing whatever work should be done as well as any diagnostics or auditing that may be necessary. In this scenario the source is decoupled from the work handler by the queues.
Why not both?
That said, since both of the services basically do the same thing, you can easily write interfaces for sending and receiving messages, like these two:
public interface ISendNotifications {
void SendNotification(string topic, string message, string subject);
}
public interface IReceiveNotifications
{
void HandleAndDeleteMessage(Action<string> messageHandler);
}
Once you have interfaces (these or your own) that abstract away the details of the underlying provider you’re using, you can use whatever messaging system you like. That might be Azure, or Amazon, or it could be your own NServiceBus, RabbitMQ, MassTransit, or other system. Assuming you’re happy to use a hosted service like Azure or Amazon, another option becomes available – having a backup.
Use One Service as Primary, and Another as Backup
Even big cloud services like Amazon and Azure occasionally have outages, like the one Amazon had on 28 February 2017. These are quite rare, but if you want to avoid major impact on your processes from such outages, you can code against interfaces and then create an implementation that will use two services, one as primary and one as backup. In the event of errors to the primary service, the secondary service will be used. On the destination side, you would simply write handlers that would listen to both endpoints for messages. One would be active most of the time – the other would only be active in the event of an error to the primary service provider. This adds a bit of complexity to the handler, since it needs to monitor multiple queues from different cloud providers, but we’ll address that in the next section.
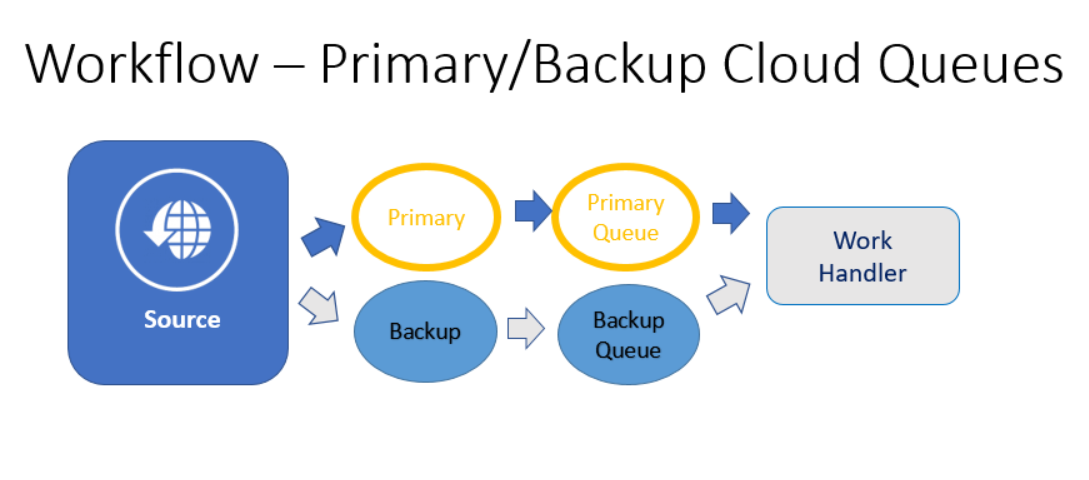
You could add multiple handlers, one per cloud queueing provider, and still use the diagram shown above, only sending to the backup provider in the event of errors to the primary. However, that might allow problems to creep up undetected in your backup configuration…
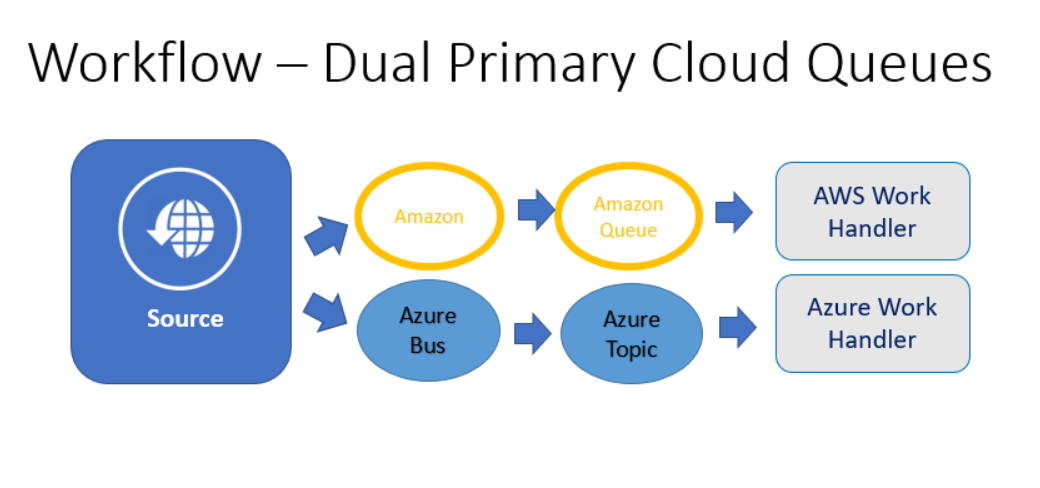
Or Better, Both as Primary
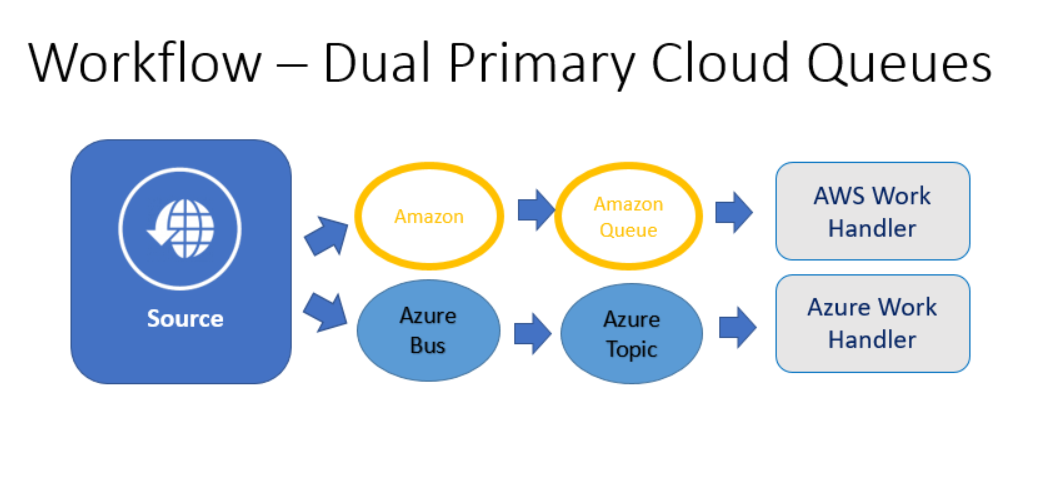
I have a saying about backup plans: “Hope is not a plan.” If you’re not regularly verifying your backup plan works by performing all of the steps that would be required if your backup becomes necessary, you don’t really have a backup plan. You have hope. Or backup prayers. If you follow my advice above and configure both systems and use one as the primary, and the only time the backup comes into play is very rarely when the primary has problems, it’s quite likely that some problem will have arisen that will prevent your backup plan from working. Your subscription will have expired, or your security token, or your message format will have changed or some other random thing and all of the effort you put into having a backup plan will end having been wasted.
Instead, write to both systems, all the time. Write separate (but identical) handlers that differ only in their implementation of which queue they receive messages from. And have your message senders randomly choose which system to which to send their messages (or, if you prefer, send 90% to whichever one is cheaper this month, but make sure you are always sending a decent amount to the less-preferred provider so that you know it’s still working as expected). This will help to ensure High Availability (HA) for your system since it is extremely unlikely that both cloud providers will be experiencing downtime at the exact same time.
Category - Browse all categories

About Ardalis
Software Architect
Steve is an experienced software architect and trainer, focusing on code quality and Domain-Driven Design with .NET.

{kind=link}